What’s Our Goal?
This is a draft chapter from my book. Here’s the Introduction and Chapter 1.
If you’d like to give feedback, do so through this Google Doc. (If you give any amount of feedback, I’ll thank you in the book!) Please give me brutal, honest feedback! If something sucks, say it!
Btw, if you’d like to be notified when I release the book, sign up here. If you’d like to support my work, please do so through Patreon (or, with ETH on StakeTree). Thanks!
Chapter 2: What Is Our Goal?
Before we understand our context in 2018, let’s ask a question that’s abstracted away from any given context, namely: “What is our goal? How can we do the most good in the world?” In theory, we can answer this question in a way that would apply any point in time: 10,000 B.C.E., 2018, or 500,000 C.E. So the answers to this question won’t be specific to our time (“solve malaria”), but will be abstract (“do the thing that makes more people happy”). I like to think of this as our “Deep Why”. i.e. When we act in the world, why are we doing it? Then recursively asking the “why” question again and again until we find our “deepest” why. If FluidMode is our Deep Framework, then what is our Deep Why?
To answer these questions, we’ll look at a couple of the key Tensions in answering this question, propose a relatively simple two-dimensional graph, and explore the spiritual/philosophical angle.
Key Tensions/Dialectics/Dances
There are a number of interesting tensions that surface from the question “How can we do the most good in the world?” As we explore these tensions, we’ll look at Effective Altruism (EA), which is a movement of intentional/philosophical folks aligned around answering that question. As you’ll see, EA doesn’t necessarily have the right answers, but they have explored extreme answers that can give us insight.
Tension #1: Are ends or means more important?
When trying to do good, one of the 1st questions to ask is: “Should I focus on my actions or the outcomes of my actions?” It’s not clear which side is better. One could have super well-intentioned actions that resulted in bad outcomes (perhaps like a do-gooder trying to help poor folks in a developing country, but not understanding their local context). Or the opposite: a super good outcome that resulted from an “evil” action (perhaps your political party winning an election through voter fraud). This tension is reflected in the classic quote: “Do the ends justify the means?” In more academic terms, this is a dialectic between consequentialism (focusing on consequences) and deontology/virtue ethics (focusing on matching your actions to some duty, moral imperative, or virtue set like “be honest”).
Means
In some ways, I’m a huge fan of focusing on means. For one, you can’t really control the outcomes of your actions. e.g. You can’t control others’ emotions, what they’ll do with money, or how complex systems interact. Trying to control these outcomes is futile. Instead, you should just concentrate on your own mindset and make sure you have a great process. (Btw, this is my favorite response mechanism for stress — when you’re stressed, bucket the world into the things you can control and the things you can’t control. You’ll realize that pretty much everything is out of your control and you can only control your response!)
In addition, I’m hyper intentional, a necessary condition to achieve “good means”. (You need to be intentional about both the {virtue set} you’re matching with and how your actions align with it.) This often leads me to virtue ethics. For example, I’m super pro honesty/transparency and super against stealing/upholding commitments. Let’s look at an extended “slippery slope” example:
- Most of us likely think that stealing clothes from a family store is bad. They’re offering a good for $30 and you’re taking it (without telling them) for $0.
- What about getting a water cup from a fast food restaurant (like McDonald’s) and then filling it with soda (like Coke)? I used to do this a lot. Why would I pay $3 for a soda when it’s just some high fructose corn syrup, color dye, and water? Especially when the companies are massive multinational corporations like McDonald’s and Coke. It barely effects them. And they are bad for the world — their primary outputs are obesity and environmental pollution. But again, like above, you’re stealing. They (the restaurant and soda) are offering a good for $3 and you’re paying $0 (and lying to the cashier about your intentions — saying “water please!”). Sure, you might think they should charge only $0.50. But they don’t. Their offer is $3, and you can go somewhere else if you want cheaper soda that’s better for the world. I’d say it’s technically “not as bad” as stealing the $30 t-shirt from an old woman’s shop. But they are both stealing. There’s a binary answer (stealing or not?) and then a gradient afterwards (if stealing, how bad is it?).
- Let’s look at a more extreme example: using AdBlock. As of December 2016, 615M devices block ads (11% of the global population). At first glance, this doesn’t seem harmful at all. Ads often ruin your browsing experience, the play into a extractionary consumerist culture, and a single ad often costs less than $0.01 to show. But when you get away from these specifics, the underlying mechanism of AdBlock is the same as stealing a t-shirt. Someone has spent their time producing content for the internet. They have decided to make a bit of money from it by showing some ads. They’re saying “the cost of viewing this content is [15 seconds of your time]”. And when you put on AdBlock you’re saying “I understand that you want me to do something to view your content. There’s a clear contract/commitment. I don’t want to do that, but I still want to get your content. So I’ll block your ads and still consume your content. K thanks bye.”
- These days I don’t steal t-shirts, Coke, or internet content (though I used to do the last two!). Let’s look at a final example I’m wrestling with these days — paying for carry-on bags on flights. I travel a lot for work but am super cheap, so I fly on “ultra low-cost” carriers. They have cheap tickets, but if you want to bring anything else besides a “personal-item” (like a small purse), you need to pay extra. I bring on a large backpacking backpack that is definitely larger than a personal item. If I was “playing by the rules”, I would need to pay to check it or carry it on. But I don’t. I just bring it on the plane then put it in the overhead carry-on bin. In some ways, this is fine: the size restrictions seem arbitrary and they almost always have the extra space. But the underlying mechanism is the same as the ones above. They’re offering something for $30, and I’m saying “I’d like that thing, but I don’t want to pay you for it. So I’ll just do it anyway and lie/hide my actions from you.”
Woof. After typing that final bullet point, my gut contracts and my chest tightens. I’m pretty sure I should stop “hacking” the airplane baggage system. When people want my value ($ or time) in exchange for their value (goods or services), I should comply by their contracts (or go somewhere else).
This is all to say, focusing on means makes sense because both: a) You can’t control most outcomes and b) There are powerful virtues like honesty that, when broken, extinguish trust and unsettle your deep intuitive sense of “right”.
Ends
Instead of means, we could also focus on ends. We also call this “outcome-driven” or consequentialism (optimizing for consequences). Note that consequentialism doesn’t define the specific outcome metric to optimize for, it purely states that we should optimize for outcomes generally. Therefore, utilitarianism is a kind of consequentialism (where you optimize for maximizing happiness and minimizing pain).
Intuitively consequentialism is a powerful framework because outcomes actually affect people. i.e. It doesn’t matter if I felt good doing X, it matters what impact X had on myself and others. The UN’s 17 Sustainable Development Goals are consequentialist (they are sustainable development goals, not virtue sets). In addition, consequences are easier to measure than virtue sets. For me personally, consequentialism is also a deeply intentional practice (you need to be intentional about what your goals are and then measure yourself against them).
In general, I find that I judge my actions more with consequentialism than virtue ethics. Why is this? And how would I convince you to be 90% consequentialist and 10% virtue ethics? First off, at a high-level, I think the most important thing is that you’re being intentional/reflective about your actions/impacts. I don’t really care if, during the reflection process, you are primarily thinking in terms of virtue ethics (i.e. if your actions aligned with a given {virtue set}). I just think it’s awesome you have a process.
But if you go a click further, I’ve found that consequentialism generally “beats” virtue ethics. Though I’m not entirely sure why, I think it’s because consequentialism can answer most objections by turning them into consequences. In other words, consequentialism is powerful because it can turn any objection into a consequence, therefore subsuming that objection into its worldview. It’s a bit strange, so let’s look at a hypothetical example.
Here’s a classic objection to consequentialism called the trolley problem. Let’s say a train (trolley) is coming down the tracks. It will either hit (and kill) 2 children or 1 child. The mother of the single child must choose between killing her child and saving 2 children, or saving her child and killing the other 2. From a “purely consequentialist” perspective, she should choose to kill her child and save 2, right? (Because 2 > 1.) But wait, isn’t that an awful consequentialist world to live in? One in which mothers are killing their own children? Consequentialists would have two responses to this:
- We haven’t agreed which outcome to optimize for yet. If we’re operating in purely utilitarian terms, yes 2 is indeed greater than 1, but we might be optimizing to minimize another outcome like “number of children killed by their mothers”. We may be consequentialist, but we need to choose which outcome we’re optimizing around (and we haven’t agreed on that yet).
- A world in which mothers kill their children is indeed a bad outcome. Consequentialists agree with you. It’s an “externality” of the single decision, but we should take all externalities into account when making the decision. In other words, the decision is not just 2 vs. 1. It’s 2 (and mother killing stranger’s children) vs. 1 (and mother killing her own child). 2 + MomKill > 1 + MomSave.
As you can see from the two responses above, a consequentialist framework is good at going to the meta-level from two directions: 1) Evaluating and debating the goal itself. 2) Expanding the scope to include externalities of actions. In other words, when people object to consequentialism, they’re often doing so by claiming “bad consequences”!
For me, the most powerful critique of consequentialism is that we can’t control the outcomes of our actions. Why would we optimize for outcomes that we can’t control? The mother above can try all she wants to make a choice, but what happens if the electricity goes out and her child dies? Should we “blame” her? In the end, there’s no way to escape from this objection. Instead, I like to think of consequentialism like the scientific method — as a long-term process that vectors towards morality.
The other classic criticism of consequentialism is that it is too difficult to applyit. i.e. You might agree with consequentialism in the abstract, but think that it is too difficult to determine correct metrics, measure impacts, etc. To answer this objection, let’s dive into Effective Altruism (EA), a group of Consequentialist Maximalists that have been applying consequentialism to the real world for ~10 years. I’d count myself as an Effective Altruist, so take this all with a degree of salt.
Effective Altruism
So what exactly is Effective Altruism? On the official website,EffectiveAltruism.org, they both answer from the highest question level: “Effective altruism is about answering one simple question: how can we use our resources to help others the most?” and from the process-level: “Effective altruism is about using evidence and careful reasoning to take actions that help others as much as possible.” I like both of these answers. The 1st is aligned around a question (rather than an answer) and the 2nd is aligned around a process (rather than an outcome). Also, it’s worth noting that EAs are not consequentialist “by nature” (i.e. they didn’t necessarily start there). Instead, the came to consequentialism as a conclusion based on trying to answer a question. EA is both the mindset described above (how to do the most good?) and a community of folks based around that mindset (the Facebook group has 15,000 people). Let’s explore how EAs try to apply consequentialism to the real world.
So how do EAs choose what to measure? What counts as “good”? This is (clearly) a difficult question to answer. Should we optimize for meaning, clarity, health, or happiness? EAs choose to optimize for happiness and something specifically called a “quality-adjusted life year” or QALY (or rather, the cost-effective version of this, QALYs per dollar). A QALY is just one year of life, adjusted for how good it was (that’s what we mean by “quality-adjusted”). In other words, if you were being tortured for a year, that shouldn’t count for as much as if you were tanning on the beach for a year. From an EA perspective, decisions should be evaluated from the perspective: “Which would give the world more QALYs/$?” (Many world health organizations use a similar metric — disability-adjusted life year or DALY — to measure the effectiveness of their interventions.)
First off, it’s worth noting that EAs explore questions on two levels: cause prioritization (what causes should we concentrate on?) and cost-effectiveness (within a cause, what actions can we take to have the most impact?).
Your first response might be skeptical. How do they determine quality? What if a blind person is more happy with their life than a seeing person? Aren’t there qualitative things you can’t measure quantitatively? Isn’t this dehumanizing to treat everyone as a number? We’ll get to these objections in a bit. But first, let’s explore some interesting cases that come from optimizing for QALYs/$.
- Ignore Bureaucratic Overhead: First off, it’s interesting to note that we’re not optimizing for a traditional non-profit metric like minimizing “% of bureaucratic overhead”. Which organization would you rather donate $100 to — one that spends $50 on internal overhead, but saves 1,000 lives? Or one that only spends $10 on overhead but only saves 10 lives? I’d rather save 100x the amount of lives. From the QALY/$ perspective, impact is what matters (not how you get there). As is to be expected with consequentialists, the ends justify the means.
- Earning-to-Give: Another interesting conclusion that results from an EA mindset is the idea of “earning-to-give”. Instead of working in a high-impact job (like a malaria net non-profit), you can make a lot of money and then give it to those effective charities. Versions of this concept can feel pretty gross. Want to make a big impact in the world? Work for a soul-crushing oil company on Wall Street, just eat rice and beans, and give your money to poor people. Now that’s Effective Altruism!
I give these examples not to turn you away from the EA mindset. Clearly, we should try to have non-profits with low overhead. And we shouldn’t work in industries that are bad for the world. Instead, I just give these examples to show you extreme bounds of what happens when you start optimizing for QALYs/$.
Tension #2, Moral Patienthood: Whose QALYs should we optimize for?
The 1st big tension was — should we optimize for ends or means? Assuming you answer that question with (mostly) ends, then the question becomes — what outcomes should we optimize for? Within the EA mindset, this question becomes — whose QALYs “count”? Should animals, people in the future, and AI all have the same weight as those alive today? Philosophers call this “moral patienthood” and it’s a difficult question. EAs try really hard to answer this question. e.g. In 2017 the Open Philanthropy Project (an EA-inclined nonprofit) released a 140,000-word “Report on Consciousness and Moral Patienthood” that includes over 400 footnotes and 1200 sources in its bibliography. Let’s examine two of the biggest tensions in moral patienthood:
- Animals: How should we balance animal vs. human lives? If I could save 100s of dolphin lives or 1 human life, which should I do? This is why, at the Cause Prioritization level, there’s a subset of EAs who are trying to reduce factory farming (as opposed to developing world health, for example). As I wrote earlier, 70 billion land animals are farmed every year, and an additional trillion sea animals are farmed. Even if you just think that an animal life is worth 1/10,000th of a human life, those numbers start to add up pretty fast. There’s another strange offshoot from this mode of thinking: Reducing Wild Animal Suffering. There are many more wild animals than there are farm animals (by several orders of magnitude). Why not help them?
- Long-term Future: This is another funny one. Instead of just thinking about helping the people already alive, we also think about those who are yet to be born. Once you think about “future people”, you quickly realize that are going to be a whole bunch of them. Looking backwards, since 50,000 B.C., there have been about 108 billion homo sapiens (of which 7.5 billion are alive today). Looking forwards, we could be around for millions of years (and expand into the universe), which means a lot of “future people”. The philosopher Nick Bostrom calls this “humanity’s cosmic endowment” — we (humans) were gifted an awesome endowment/opportunity for (possibly) trillions of humans to live happy lives across the entire universe for billions of years. Once we start caring about “future people”, then it quickly becomes clear that the downside of human extinction is massive: it’s not just losing the 7.5 billion people alive today, but the trillions of people who would’ve lived later.
Maximizing the Graph of Humanity’s Cosmic Endowment
Again, the goal of this chapter is to determine “what is our goal?” I’ll mostly use an EA perspective to define the goal. It sounds something like: “try to make lots of happy people/beings for a very long time”. I like to imagine it as a graph where the y-axis is “total happiness” and the x-axis is time. The goal is to maximize the area under the curve. i.e. Make the x-axis super long (don’t go extinct) and make the y-axis super high (make everyone happy!). Here’s a hopeful example of what this (rough) graph could look like:
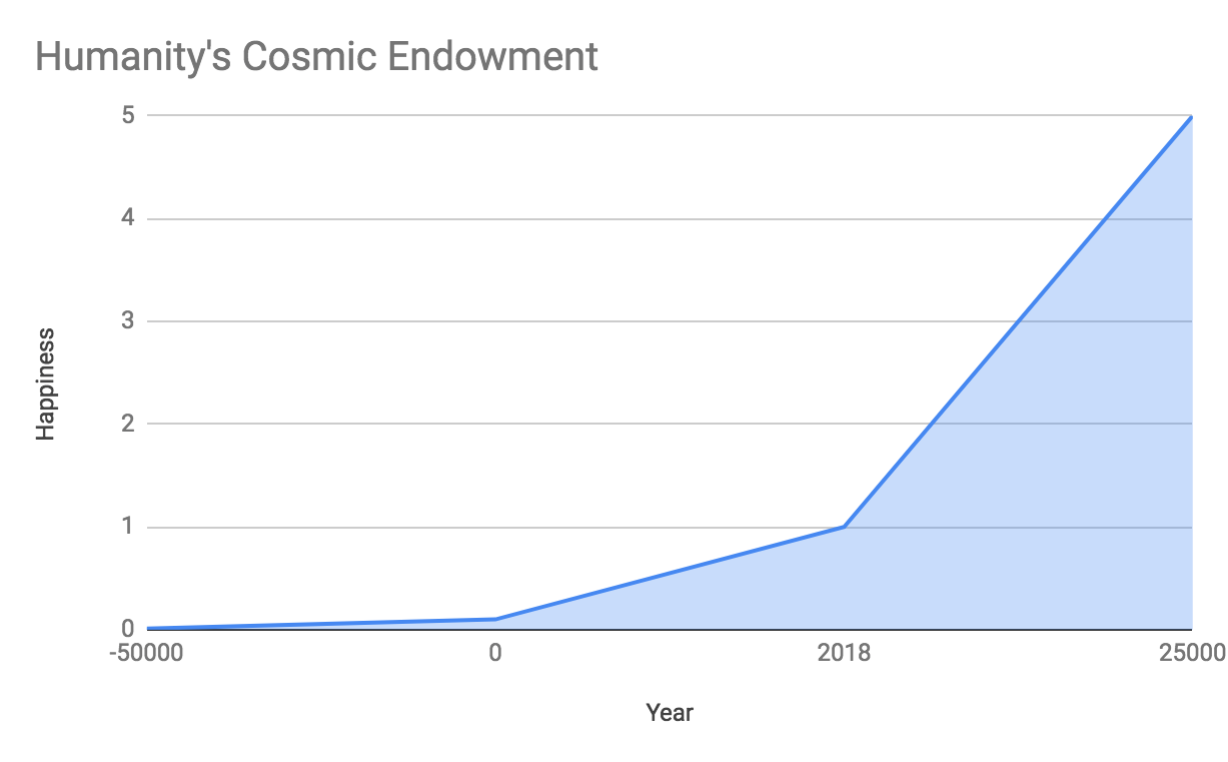
(But remember the graph goes to the right for a very very long time (trillions of years?). 2018 is but a tiny blip.)
In addition to “maximize the graph!”, here are a couple other ways to think about the goal.
- Playing an Infinite Game: If you imagine humanity as a game, it would be cool to make it a super long (infinite!) game. There’s actually a whole book called “Finite and Infinite Games” that distinguishes between finite games (ones where you play to win) and infinite games (where you play to continue playing).
- Making Humanity Antifragile: Another way to think about “extending the x-axis” is saying “we want to make humanity exist, no matter what changes in the future”. This is essentially Taleb’s concept of antifragility — systems that actually get better as a result of change/volatility.
- John Rawls’ Original Position: This is a cool thought experiment that the philosopher John Rawls’ developed in 1971. The idea is this: pretend you’re determining the structure of society that you’ll inhabit. But, when you’re determining the structure, you’re operating behind a “veil of ignorance” — you don’t know where in that society you’ll be (you could be a slave or a ruler). Given that veil, how should you design society? In general, this would lead you to create a structure (called maximin) that’s pretty good for most people (because you could be any of them!). This leads to another way to think about our goal: we’re trying to make a great societal structure so that anyone born into it (at any point in time) is happy (and actually gets born!). We can’t go back in time to change stuff in the Dark Ages, but we can vector our future towards a positive one (that exists).
Conclusion
In chapter 1, I argued for FluidMode as a meta-framework to understand the world (actively try to take multiple perspectives!). In this chapter, we looked at balancing ends vs. means when we’re trying to do good. I take a mostly ends-driven perspective (consequentialism!) led by folks like Effective Altruists. Within this consequentialist perspective, we can view the world as a graph of happiness over time. Our goal? To maximize the integral. And remember — you are allowed disagree with this goal!
Note that this goal (Maximize the Integral!) changes how we understand our current context and the actions we should take (given that context). Scope determines the kinds of information we find relevant. i.e. In general, I’m going to look to make humanity “survive” longer, while trying to make life better for those who are already here. e.g. Even though my mother has early-onset Alzheimer’s, I’m not going to “optimize” for her well-being (though I clearly love and care for her more than a random QALY).
So now we’ve understood our goal (Maximize the Integral!). What should we do to help out? This is connected to our current context (how are we doing and what is the situation?), so let’s look at that. But actually, I’m going to be an Abstraction/Tool/Framework/Teacher Maximalist and instead ask the question: “How can we understand our context?” (Rather than ask the question: “What is our context?”) Let do that now.
Support me on Patreon/StakeTree!
Thanks to Collin Brown, Mike Goldin, John Desmond, Paras Chopra, Andrew Cochrane, Sandra Ro, Harry Lindmark, Jonny Dubowsky, Sam Jonas, Malcolm Ocean, Colin Wielga, Joe Urgo, Josh Nussbaum, John Lindmark, Garry Tan, Eric Tang, Jacob Zax, Doug King, Katie Powell, Mark Moore, Jonathan Isaac, Coury Ditch, Ref Lindmark, Mike Pratt, Jim Rutt, Jeff Snyder, Ryan X Charles, Chris Edmonds, Brayton Williams, Brian Crain, David Ernst, Ali Shanti, Patrick Walker, Ryan Martens, Kenji Williams, Craig Burel, Scott Levi, Matt Daley, Lawrence Lundy, Peter Rodgers, Alan Curtis, Kenzie Jacobs, and James Waugh for supporting me on Patreon! Thanks to Storecoin, Griff Green, Radar Relay, district0x, Niel de la Rouviere, Brady McKenna, and some anonymous others for supporting me on StakeTree! Thanks to KeepKey for sponsoring the show! Please use them/check them out!
Hit me up on Twitter!
Disclaimer: I own less than $5000 of any given cryptocurrency, so my monetary incentive is not too aligned with Bitcoin, Ethereum, etc. :)